近幾天花了一些時間研究一下Hadoop,幾年前在使用HBase時有稍微玩一下
但沒有深入去瞭解,目前正在學習使用docker,看到docker hub上有人已經包好hadoop cluster
就建個cluster來測試一下
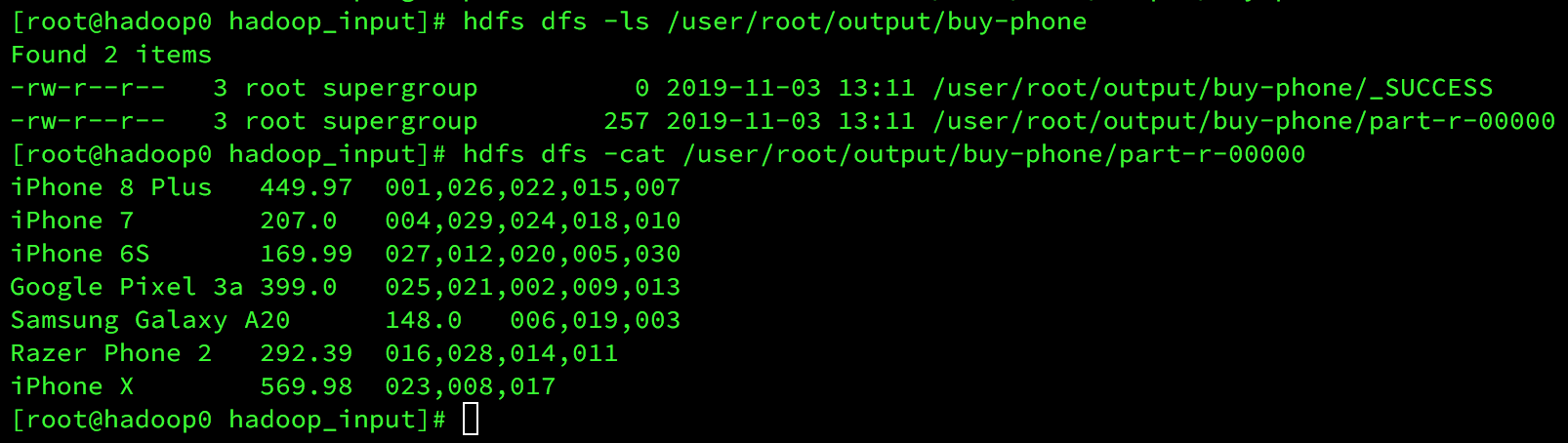
啟動hadoop cluster成功
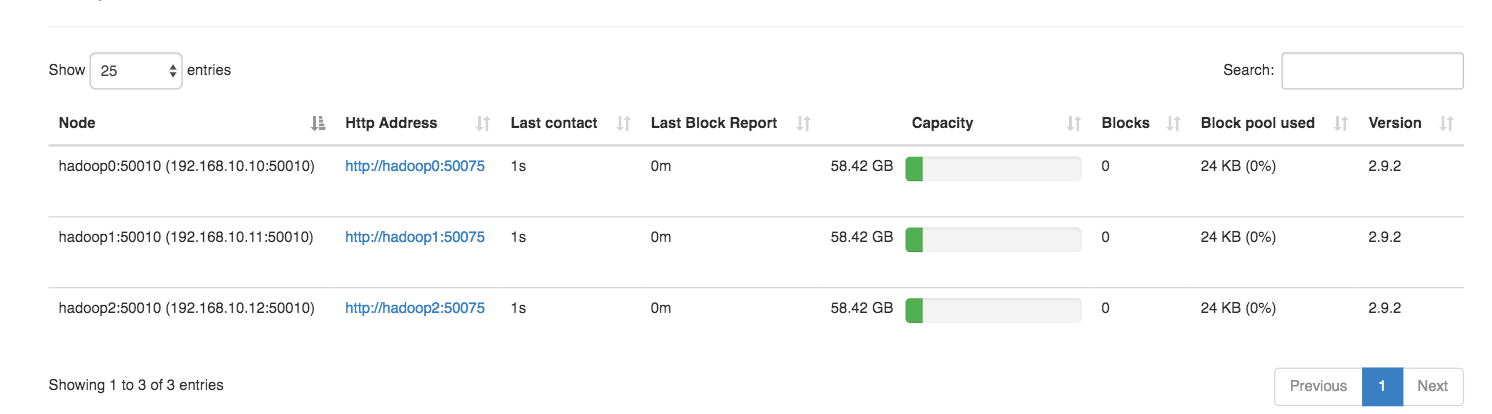
這次主題為客製化Writable,將資料包裝為Serializable Object後傳輸
為了傳輸效能Hadoop有自己的序列化,而不直接使用Java自帶的序列化
同樣是序列化,但是Java序列化產生出的byte stream包了較多的物件資訊(重量)
Hadoop的序列化自帶的序列化資訊比較簡潔(輕量)
要使用Hadoop的序列化必須implements Writable
它會要求Override write和readFields作為序列化與反序列化資料轉化為byte stream
此次使用場景為統計各個產品被哪些顧客購買
資料分為三種:
顧客資料(customer.txt)
| customerId | productId |
|---|---|
| 001 | 01 |
| 002 | 04 |
| … | … |
產品資料(product.txt)
| productId | productName |
|---|---|
| 01 | iPhone 8 Plus |
| 02 | iPhone 7 |
| … | … |
產品價格(price.txt)
| productId | productPrice |
|---|---|
| 01 | 449.97s |
| 02 | 207.00 |
| … | … |
先建立一個CustomerBean將來資料從map傳給reducer時可用
這裡要注意write和readFields在做序列化和反序列化時“順序”需要保持順序一致
才不會解析錯誤
1 | public class CustomerBean implements Writable { |
接下來建立一個BuyPhoneMapper將資料封裝到CustomerBean後傳給reducer處理
因為資料源有三種,所以第一步需要在setup時預先判別資料源類型,這裡使用檔名做為區別
第二步根據資料類型封裝資料到CustomerBean此時也需要紀錄資料源類型,方便在reducer時判別
第三步將資料寫入context,分組key為productId(三種資料源共通使用),value為CustomerBean
1 | public class BuyPhoneMapper extends Mapper<LongWritable, Text, Text, CustomerBean> { |
BuyPhoneReducer統計手機產品被哪些顧客購買
第一步根據資料源類型取得顧客資料(customer)產品名稱(productName)和產品價格(productPrice)
第二步統計顧客使用的產品
第三步依據產品名稱(productId)與產品價格(productPrice)分群(key),統計買該產品的顧客們(customerIds)輸出為value
1 | public class BuyPhoneReducer extends Reducer<Text, CustomerBean, Text, Text> { |
到最後一個步驟了,包裝成hadoop任務(job),yarn可以根據此設定進行執行
當job送出時會也會包含Configuration的xml設定一起送出
這裡我將Job多包裝一層,比較方便閱讀和使用
1 | public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { |
將產品資料寫入到hdfs

執行job

執行完成
查看結果